Web Scraping Trending from Tumblr with Web Data Extractor
In this article, we will tell you how to scrape trending from Tumblr using ScrapeStorm’s “Smart mode“.
Introduction to the scraping tool
ScrapeStorm (www.scrapestorm.com) is a new generation of Web Data Extractor based on artificial intelligence technology. It is the first scraper to support both Windows, Mac and Linux operating systems.
Introduction to the scraping object
Tumblr is a microblogging and social networking website founded by David Karp in 2007, and owned by Oath Inc. The service allows users to post multimedia and other content to a short-form blog. Users can follow other users’ blogs. Bloggers can also make their blogs private.
Official Website: https://www.tumblr.com/
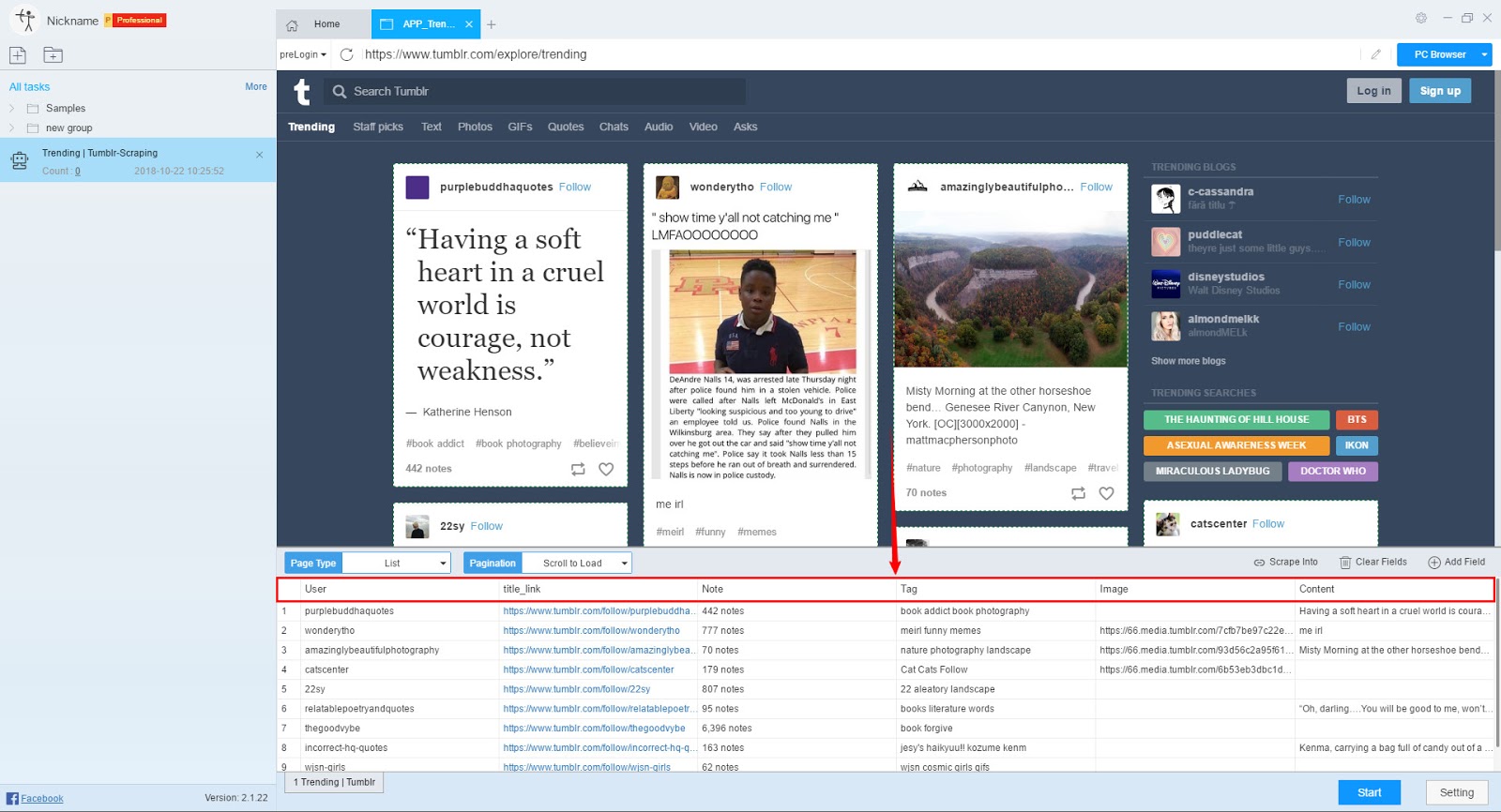
Scraping fields
User, title_link, Note, Tag, Image, Content
Function point directory
Preview of the scraped result
Export to Excel2007:

1. Download and install ScrapeStorm, then register and log in
(1) Open the ScrapeStorm official website, download and install the latest version.
(2) Click Register/Login to register a new account and then log in to ScrapeStorm.

Tips: You can use this web scraping software directly, you don’t need to register, but the tasks under the anonymous account will be lost when you switch to the registered user, so it is recommended that you use it after registration.
2. Create a task
(1) Copy the URL of Tumblr
Click here to learn more about how to enter the URL correctly.

(2) Create a new smart mode task
You can create a new scraping task directly on the software, or you can create a task by importing rules.
Click here to learn how to import and export scraping rules.

3. Configure the scraping rules
(1) Manually select
If you are not satisfied with the automatically recognized data or the effect of recognition is not good, you can manually select the list on the page.

(2) Set the fields
Intelligent mode automatically recognizes the fields on the page. You can right-click the field to rename the name, add or delete fields, modify data, and so on.
Click here to learn how to how to configure the extracted field.

Add or remove fields as needed, and rename the fields. The results of the field settings are as follows:
(3) Manually set the page
Some web pages have special buttons on the next page, and the system may not recognize them. In this case, you need to manually set the page to “Scroll to Load”.
Click here to learn how to manually select the page.

4. Set up and start the scraping task
(1) Running and Anti-block settings
Click “Setting”, set waiting time based on web page open speed. You can check “Block Images” and “Block Ads”. The anti-block settings follow the system default settings. Then click “Save”.
Click here to learn more about how to configure the scraping task.


P.S. “Block Images” will reduce the load time and speed up the scraping process. And this operation does not affect the scraping and downloading of images.
(2) Start scraping data
Premium Plan and above users can use “Scheduled job” and “Sync to Database”. If you want to download images, you can check “Download images while running”. Then click “Start”.
Click here to learn about scheduled job.
Click here to learn about sync to database.
Click here to learn about download images.

(3) Wait a moment, you will see the data being scraped.

5. Export and view data
(1) Click “Export” to download your data.

(2) Choose the format to export according to your needs.
ScrapeStorm provides a variety of export methods to export locally, such as excel, csv, html, txt or database. Professional Plan and above users can also post directly to wordpress.
Click here to learn more about how to view the extraction results and clear the extracted data.
Click here to learn more about how to export the result of extraction.




评论
发表评论